Meadowlark: Sheffield based computer consultancy
The TestTrac LIM system
A laboratory information management system (LIM) is a database that tracks customers samples as they are processed by a laboratory.
Typically this comprises five main stages:
- Sample registration where the samples are booked in and identified.
- Sample preparation where the samples are prepared prior to testing.
- Sample testing where the samples are tested.
- Sample certification where a certificate is produced to record the results of the test.
- Sample disposal where the sample is disposed of appropriately.
Throughout this process it is possible that large quantities of information and data is gathered, and the role of the LIM system is to manage and exploit this whilst facilitating the four processes outlined above.
The role of the LIM system is that of:
- Facilitating the recording of laboratory information
- Faciliating the retrieval of laboratory information
- Faciliating the storage of laboratory information
- Improving the quality of laboratory information
- Safeguarding that information.
- Maximising that information.
TestTrac is an example of a LIM system and it accomplishes the above in the following ways.
Facilitating the recording of laboratory information
Human beings are fallable, and the recording of information is error prone. Typing errors occur, transcription errors occur, translation errors occur, and the result can be far from satisfactory. This is not desirable in any system that issues certificates. Advanced computer software can minimise these errors in a number of ways.
As test results are entered, software like TestTrac can check the validity of the recorded result and warn the user and advise on a correction.
One of the benefits of more powerful computers is that user interfaces (the way we interact with them) have become much more sophisticated and intuitive. Well designed software like TestTrac exploits the available user interface to the benefit of the user. The implications of this are that data is easy to enter, easy to change and easy to find.
Facilitating the retrieval of laboratory information
Information that is filed away and cannot subsequently be found is not information it is a lost opportunity. TestTrac like all well designed databases is designed to maximise access to the data and therefore maximise its value. If you cannot find data on TestTrac it is highly likely that you did not enter it.
Faciliating the storage of laboratory information
LIM systems like TestTrac are particularly good at storing large quantities of information efficiently. It is possible to store a years laboratory results on a cheap pen drive, or backup a live system in seconds over a network.
Improving the quality of laboratory information
A well designed LIM system like TestTrac prevents many errors occuring by monitoring the entry of data by the user. Many sophisticated and powerful techniques can be for this purpose and these work to improve the quality of what is recorded.
Safeguarding that information.
Because of design of the LIM system, safeguarding the information is easy. It is such an easy task to produce a back up that there is no excuse to fail to do so. In fact backups can be automated.
Maximising that information
Any good LIM system like TestTrac, can perform beyond its intended role. As data accumulates, it is often the case that marketing opportunities or economies can be discovered in a laboratory that can be exploited to great effect.
Screen shot of the booking in screen of the TestTrac LIM system.
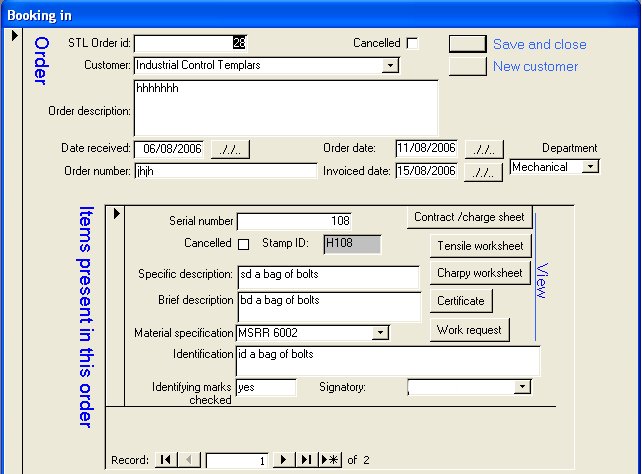
The above screen is used to enter the information about the sample as it enters the lab. From this screen it is possible to track its progress from booking to preparation to testing to certification.
Entering customer information on the TestTrac LIM system.
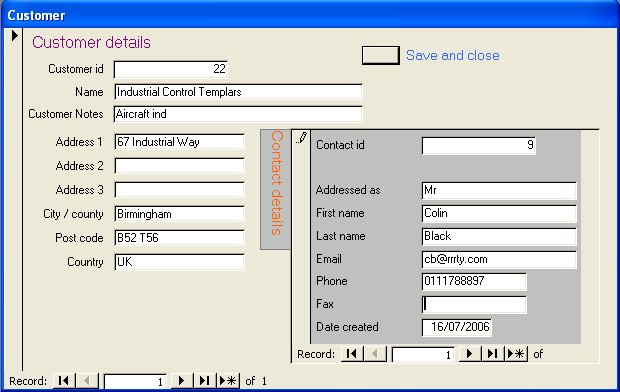
The above screen provides a single point of access to all customer information.
What you can expect from LIM systems in the future?
A LIM system is basically a database, and databases can, with the help of clever programming and perhaps some Artificial intelligence (A.I.) just get better and better. But how might they achieve this?
Better software and user interface design will quickly and effortlessly guide the user in an intuitive fashion through the workflow. This is in fact quite a tall order currently as LIM systems are often generic systems designed to capture data and have to fit any data capture bill. A user interface that more closely reflects the patterns of current data entry may have some advantages as for example it could provide more immediate user feedback and guidance.
A cleverer LIM system may also, with the help of artificial intelligence be able to draw upon previous data to look for patterns in the data in real time, and make predictions of system behaviour before the data has even been examined by the laboratory technician, but really clever A.I. may go further
What if an intelligent LIM system could, using the extensive "big data" it has at its disposal, make predictions of outcomes with novel data and variables? Neural networks do just this. This might enable new ways of processing samples that have so far been unknown.